Claude Code, Codex, Semgrep, CodeQL & Trent vs 28 CWE-Bench CVE Vulnerabilities


A few months ago a colleague asked us something that doesn’t have an obvious answer: is code scanning still relevant when LLMs already carry a lot of vulnerability knowledge in their weights?
To get a real read, we took 28 production vulnerabilities from CWE-Bench, actual fixes in actual open-source repositories and pointed five tools at them. Two static analyzers (Semgrep, CodeQL), two general-purpose coding agents (Claude Code Opus 4.7, OpenAI Codex GPT-5.3), and our own Trent Security Assessment Agent.
A few things became clear:
- All the tools can eventually surface the right kind of bug somewhere in the repo. Claude Code did this 65% of the time. Semgrep about 43%. That’s the easier half of the problem.
- The harder half is landing the finding on the file that was actually fixed. Claude Code got there 8.7% of the time. Semgrep and CodeQL both ~3.6%. Codex 1.8%. Ours 25%.
- The gap between those two columns, “I see something XSS-shaped in this repo” vs “the XSS is in DefaultHTMLCleaner.getDefaultConfiguration”, is where repository-scale security actually lives.
We don’t think the headline number means our agent is “winning.” We think it means repository-scale security is a search problem before it’s a reasoning problem, and most tools are still solving the wrong half.
Methodology, caveats, and the full per-tool breakdown below.
Why static scanners and coding agents miss vulnerabilities
AI is changing the economics of software development. Code is becoming cheaper to generate, faster to modify, and easier to ship, while securing software still depends on scarce expert attention. Large codebases were already difficult to audit comprehensively, and AI-assisted development makes the problem more acute by increasing both the amount of code and the speed at which it changes.
That imbalance creates a new challenge for software security. The question is no longer only whether a tool can recognize a vulnerability once it is looking at the right file. It is whether it can decide where to look across an entire repository, reason about what matters, and keep up with software that is changing faster than humans can realistically review.
To understand how different approaches handle that challenge, we benchmarked static analysis tools like semgrep, general-purpose coding agents like Claude Code, and our own Trent Security Assessment Agent across full-repository application security. The results show a clear ranking, with Trent meaningfully ahead of both static analysis tools and general-purpose coding agents. We discuss below what we think this ranking does and does not tell us about the architectural choices behind these tools.
Why static scanners and coding agents miss vulnerabilities at repository scale
The tools available today tend to fail in opposite ways. Pattern-based scanners like semgrep are built for coverage: they walk the whole codebase, apply rules consistently, and rarely miss a file. But they have only a shallow understanding of whether a finding matters. Reasoning agents have the inverse shape. They can understand context, intent, and exploitability far better, but they do not naturally provide systematic coverage. The security issues that often matter most in production systems usually sits between those two capabilities.
Path traversal is a good example. A scanner can flag places where user input flows into a file path, and the better ones can track that input through several layers of helper functions. For example, letting a user-controlled filename decide which file gets opened may be dangerous, but only if the application does not constrain that filename to a safe directory. The important question is whether that path is exploitable: is it reachable from an exposed endpoint, has it already been normalized, does the framework treat it as safe by convention, and can an attacker meaningfully control the final path? Without that context, broad coverage turns into noise: generic “user input reaches file path” warnings that may be valid in isolation but are not grounded in how this product handles files.
This is where general-purpose coding agents look promising, but only up to a point. A general-purpose coding agent can reason about those questions more naturally. If it is looking at the relevant endpoint, helper, and file operation together, it may correctly distinguish an exploitable flow from a harmless one. But auditing an entire repository is not just a reasoning task; it is also a search problem. The agent still has to discover the right endpoints, follow input through routing layers and helpers, identify reachable file operations, and decide which of many similar-looking flows deserve deeper analysis. Bugs slip through not because the model could not recognize the vulnerability, but because it never reached the right place to look.
That is the gap our Trent Security Assessment Agent is designed to close. Repository-scale security analysis needs both structured exploration and contextual reasoning, connected by security judgment. Our agent starts by building a threat model of the repository and then uses a vulnerability-specific security knowledge base to turn that model into concrete checks, guiding the analysis toward the places where vulnerabilities are most likely to arise and the evidence needed to establish exploitability. Static rules are useful for broad coverage, but they are shallow on context; unconstrained LLM reasoning is powerful, but uneven on coverage. Our agent brings the two together through threat model-led analysis: it gives the model a map of where to look, a methodology for what to check, and the security judgment needed to decide which flows deserve deeper reasoning. Because most existing benchmarks measure whether a tool can recognize a vulnerability once pointed at the right file, we built ours around the harder problem: determining where to look across full repository snapshots.
How we built the benchmark: 28 vulnerabilities, 22 repositories, 4 CWE classes
Our benchmark targets repository-scale application security analysis using production vulnerabilities. We built it on top of the existing CWE-Bench dataset, because it is one of the few available benchmarks that evaluates tools on real repository snapshots rather than isolated code snippets or synthetic examples. That matters for our purposes: the question we want to measure is not only whether a tool can recognize a vulnerable pattern, but whether it can navigate a real codebase and find the relevant security flow among many unrelated files, helpers, and abstractions.
CWE-Bench is constructed from vulnerability fixes in production repositories and contains four common, security-critical vulnerability classes:
- Cross-site scripting (XSS)
- Path traversal
- Code injection
- OS command injection
We sampled 28 vulnerabilities across 22 repository snapshots, balancing coverage across the four CWE classes and favoring snapshots with multiple labelled vulnerabilities where possible. We favored repository snapshots that contain multiple vulnerabilities, because that better reflects the ambiguity tools face in real assessments: a tool may identify the right vulnerability class somewhere in a repository while still missing the specific labelled issue. This setup lets us evaluate not just whether a tool can name the right kind of risk, but whether it can localize the vulnerability that was fixed.
The 5 tools we tested: Semgrep vs CodeQL vs Claude Code vs Open AI Codex vs Trent (and why)
We evaluated a mix of static analysis tools, general-purpose coding agents, and our own agent, not only to compare individual products, but to compare the main architectural approaches available today for repository-scale security analysis.
Semgrep and CodeQL represent the rule-driven static analysis category. These tools are designed to scan broadly and consistently using predefined rules or queries.
Claude Code and OpenAI Codex represent the general-purpose reasoning agent category. Rather than giving these systems custom scanners or benchmark-specific workflows, we prompted them to perform full repository security audits, which lets us evaluate how far general-purpose coding agents can get when asked to reason directly over a complete codebase.
Our Trent Security Assessment Agent represents the third approach: threat-model-guided agentic analysis. It uses structured repository exploration to decide where to look, then applies vulnerability-specific reasoning to assess whether the behavior is exploitable.
Across all tools, we used standard or publicly available configurations wherever possible, avoiding any benchmark-specific tuning so the comparison reflects how each approach is likely to perform in practice rather than how well it can be optimized for this benchmark.
What the Results Show & detection rates per tool
Detection Rate vs Category Detection Rate: what each metric means
We evaluate each tool by detection rate: the fraction of known vulnerabilities it successfully identifies. In machine learning terms, this is recall. We do not report precision, because the benchmark repositories may contain real vulnerabilities beyond those captured in the ground truth, making extra findings difficult to classify cleanly as true or false positives.
CWE-Bench labels each vulnerability with a CWE category and a set of file locations. We follow its file-labelling convention, using the files modified by the upstream security patch as the reference location. These patches were authored and merged by maintainers with direct knowledge of the root cause, so the modified files provide a useful anchor for comparison.
That said, file location is rarely unique. A single vulnerability can span an entry point, helper logic, and a sink. The labelled file should therefore be read as a consistent reference point, not the only correct place a tool could flag.
We report two metrics:
- Category Detection Rate counts a finding as a match when its CWE category agrees with any labelled vulnerability in the repository. This captures whether a tool surfaces the right kind of issue. (higher is better)
- Detection Rate is stricter: it requires both the CWE category and the file location to match the labelled reference. This captures whether a tool points reviewers to the right part of the code. (higher is better)
| Tool | Detection Rate (mean ± std) | Category Detection Rate (mean ± std) |
|---|---|---|
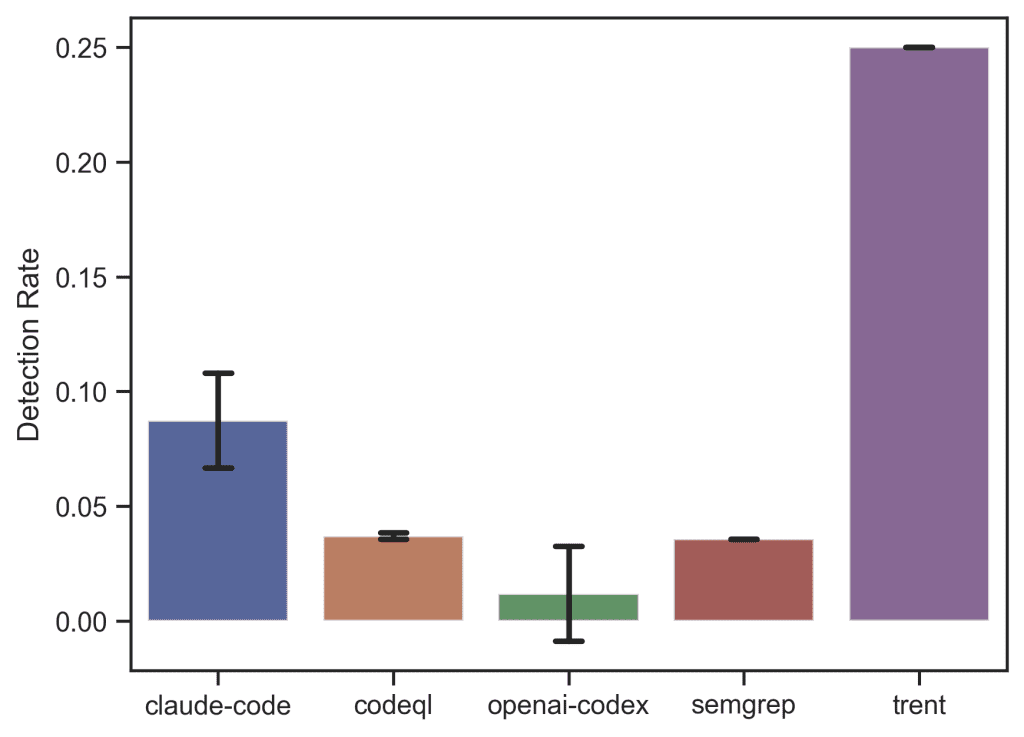
| claude-code (Opus 4.7) | 8.7% ± 2.1% | 65% ± 5.6% |
| codeql | 3.7% ± 0.1% | 11.1% ± 0.4% |
| openai-codex (GPT-5.3) | 1.8% ± 2.5% | 17.9% ± 0.000 |
| semgrep | 3.6% ± 0.000 | 42.9% ± 0.000 |
| trent | 25% ± 0.000 | 64.3% ± 6.2% |
Each tool was run three times against the same 28 vulnerabilities, with no prompt or configuration changes between runs. The table reports the mean and standard deviation across those runs.
The two metrics answer different questions. Category Detection Rate is permissive: it gives credit when a tool reports the right vulnerability class somewhere in the repository, including incidental findings. Detection Rate is stricter: it asks whether the tool grounded the right vulnerability type in the labelled location. For users, Detection Rate is the more important measure. Security teams do not only need to know that an application may be vulnerable; they need to know where the vulnerability is so they can verify, prioritize, and remediate it. A tool that reports the right issue class somewhere in the repository may be directionally useful, but a tool that localizes the issue gives reviewers a concrete place to start and makes remediation much more actionable.
We report both metrics because the gap between them is itself informative. A high Category Detection Rate with a low Detection Rate means the tool is often naming the right kind of vulnerability but not grounding it in the labelled vulnerable location. In practice, that can still send users to the wrong part of the codebase, leaving them with the work of deciding whether the issue is real, where it occurs, and what needs to be fixed.
Detection Rate: who found the vulnerability in the right file
On Detection Rate, Trent leads at 0.250, followed by Claude Code at 0.087, CodeQL at 0.037, Semgrep at 0.036, and Codex at 0.018. Because file labels are only an anchor for a larger vulnerability path, the absolute values should not be read as a complete measure of whether a tool found a real issue. They are most useful as a relative comparison under a consistent labelling rule.
Viewed that way, the results separate the three architectural approaches. Static rule engines, represented by Semgrep and CodeQL, scan broadly but rarely land on the labelled location. General-purpose coding agents, represented by Claude Code and Codex, also struggle to converge on the right file at repository scale. Trent performs meaningfully better than both groups, consistent with the hypothesis that structured exploration plus vulnerability-specific reasoning improves repository-scale analysis.
A concrete case illustrates what the stricter Detection Rate captures. In the xwiki/xwiki-commons repository, CVE-2023-29201 is an XSS vulnerability in DefaultHTMLCleaner.getDefaultConfiguration(). Our Security Assessment agent identified the correct CWE class, the correct file, and an overlapping method location, while none of the other evaluated configurations did so across their runs. The most informative miss came from Claude Code, which inspected the same file but classified the issue as CWE-611 (XML External Entity) rather than CWE-079 (XSS).
Our agent’s success here reflects how its approach is structured. Before searching for vulnerabilities, the agent first builds an understanding of the codebase and the type of application being analyzed, then derives the security requirements and risks worth investigating for that specific repository. Those context-specific risks steer it toward vulnerabilities that are plausible in this code, while a subsequent review step checks whether the evidence supports each finding. The combination lets it search deliberately without turning every broad concern into a reported vulnerability.
Category Detection Rate: recognizing the right CWE class
Category Detection Rate tells a complementary story. Claude Code’s 0.650 and Trent’s 0.643 are the two largest numbers in the table, and the gap between them is smaller than the run-to-run variation observed for Claude Code. Because the metric credits any finding in the same CWE class as a labelled vulnerability, both numbers say that the two systems routinely surface findings of the right vulnerability class in repositories that contain one.
What is informative is how this comparison looks alongside Detection Rate. Claude Code and our agent perform similarly on Category Detection Rate, but on Detection Rate the gap between them is substantial (0.087 versus 0.250). Read together, the two systems are roughly comparable at noticing that a repository contains a relevant CWE, but they differ sharply in how often that recognition lands on the file actually responsible. This is the search problem general-purpose coding agents face at repository scale, and it is consistent with the argument we made in §”Why Existing Tools Fall Short”: guessing the right vulnerability class is the easier half of the task, locating it is the harder one.
A similar pattern appears, in a different form, between the two static analysis tools. Semgrep and CodeQL sit at nearly identical Detection Rates (0.036 versus 0.037), yet Semgrep’s Category Detection Rate is much higher (0.429 versus 0.111). Semgrep’s rule set flags more candidates in the relevant CWE class, but neither tool reliably commits to the file location of the labelled vulnerability.
Why reporting more findings doesn’t mean finding the right one
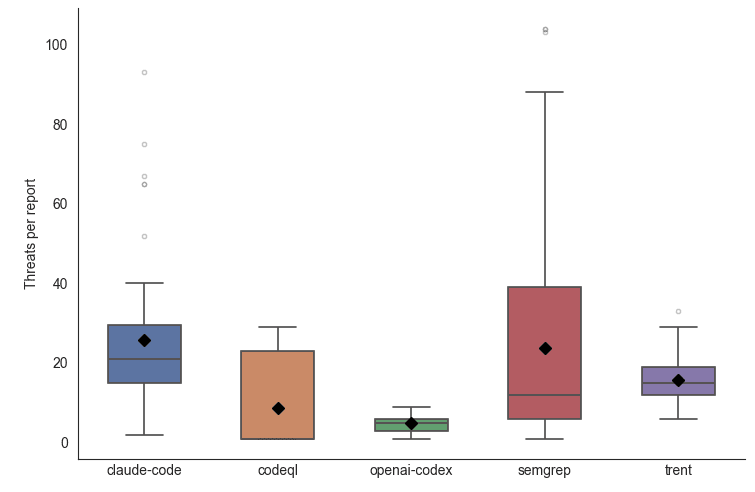
To understand the gap between Category Detection Rate and Detection Rate, we also looked at how many findings each tool reported per repository. The boxplot shows the distribution of reported findings: the line marks the median, the box covers the middle half of observations, the whiskers show the broader range, and individual points mark outliers. This is not a “lower is better” chart: it measures reporting volume. A tool that reports many potential vulnerabilities has more chances to mention the right CWE class somewhere in the repository, which can raise Category Detection Rate. But that does not mean it found the labelled vulnerability. Detection Rate is stricter: it asks whether the tool identified the right vulnerability type in the file associated with the known fix.
This distinction helps explain the results. Claude Code and Semgrep often report more candidate issues, which can make them look stronger on Category Detection Rate. But their lower Detection Rate suggests that many of those reports are not landing on the labelled vulnerable location. Trent reports fewer findings than the broadest reporting tools but is more often grounded in the part of the codebase responsible for the benchmark vulnerability.
Across the three runs, Claude Code and Codex returned different findings each time, while Trent and Semgrep returned identical recalls. This illustrates a known challenge with LLM-driven systems: even with the same prompt and repository, they may explore different paths and surface different issues. Trent is better able to control this nondeterminism because its analysis is guided by a structured threat model and vulnerability-specific review process, rather than relying on unconstrained model exploration.
Repository-scale security is both a search and a reasoning problem
Pulling these patterns together, rules surface plenty of candidates within the relevant CWE classes but rarely flag the labelled vulnerability itself, general-purpose coding agents can often recognize the right vulnerability class once they reach the relevant code, but they do not explore repositories systematically, and our agent achieves meaningfully better localization than either. The pattern is consistent: repository-scale security assessment depends not only on reaching the right code, but on bringing the right security context to that code.
At repository scale, static analysis can provide repeatable coverage across the codebase, while agent reasoning can interpret context, intent, and exploitability. But reasoning is only as useful as the frame it is given. Even when an agent reaches a relevant endpoint or sink, it still needs to understand the repository’s architecture, trust boundaries, exposed surfaces, sources of user input, sensitive operations, and existing mitigations to ask the right security questions. Without that threat model and repository understanding, the agent may inspect the right location but follow the wrong line of reasoning.
That is what Trent’s Security Assessment agent is designed around. It uses static analysis within a threat model-led analysis process, so static signals help guide both exploration and deeper reasoning. It first builds an understanding of how the repository is structured and where security-relevant behavior is likely to appear. Vulnerability-specific security knowledge then turns that model into concrete checks: which sources and sinks matter, which sanitizers are relevant, which mitigations change the risk, and what evidence is needed to establish exploitability.
This is the direction we are continuing to build toward: security assessment agents that combine systematic repository exploration with the judgment of an experienced security reviewer. The goal is to reason about findings in the context of how the actual repository behaves, so the system can move beyond vulnerability-shaped patterns and identify the issues that are truly reachable, exploitable, and worth reporting.
If you’re shipping production AI agents and your existing AppSec tools aren’t covering the new attack surface, that’s the problem Trent works on. Try Trent on your codebase.
FAQs
Can AI agents find security vulnerabilities better than static code scanners?
Sometimes, and the answer depends heavily on how the agent is built. On our CWE-Bench run, the gap between the best and worst AI agent was 14x (25% vs 1.8% Detection Rate), so “AI agent” isn’t a coherent category for this question. What seems to matter is whether the agent has a way to decide where to look across a large repository, not just whether it can reason once it gets there. Static scanners are good at the first half (systematic coverage) and weak on the second (judgment about exploitability). General-purpose coding agents like Claude Code or Codex have the inverse strengths. The tools that did best on our benchmark combined both.
Is Claude Code or OpenAI Codex better at finding vulnerabilities?
On our 28-vulnerability subset of CWE-Bench, Claude Code (Opus 4.7) landed on the labelled vulnerable file 8.7% of the time. OpenAI Codex (GPT-5.3) got there 1.8% of the time. Both tools also showed high run-to-run variance, same prompt, same repository, different findings each run. That’s not necessarily a flaw; it’s a known property of LLM-driven systems exploring large search spaces. Neither tool was wrapped in security-specific scaffolding for our run. A team that built a custom security workflow on top of either model would almost certainly see different numbers.
What is CWE-Bench?
CWE-Bench is a public benchmark built from real vulnerability fixes in open-source Java repositories. Each entry pairs a repository snapshot from just before a security fix was merged with the file(s) the maintainer modified. The dataset covers four common vulnerability classes, cross-site scripting, path traversal, code injection, and OS command injection, and was assembled by the IRIS-SAST research group.
What is agentic security analysis?
AI agents that audit full repositories by combining structured exploration (deciding where to look across a large codebase) with vulnerability-specific reasoning (deciding whether a candidate flow is actually exploitable). The contrast is with the two existing approaches, rule-driven static analysis (broad coverage, no judgment about exploitability) and general-purpose coding agents (better judgment, no systematic coverage).
Is Semgrep or CodeQL more accurate for vulnerability detection?
On our CWE-Bench subset, Detection Rates were nearly identical: Semgrep 3.6%, CodeQL 3.7%. The more interesting gap was on Category Detection Rate, where Semgrep scored 42.9% and CodeQL 11.1%. Semgrep flags more candidates in the relevant CWE class; CodeQL is more conservative. Neither reliably pointed to the labelled vulnerable file, which is the metric we cared about most in this evaluation. Worth noting: both tools have decades of tuning behind them, and the configurations we used were defaults. A security team running custom rules for their stack would likely see different numbers, that’s true for any rules engine.