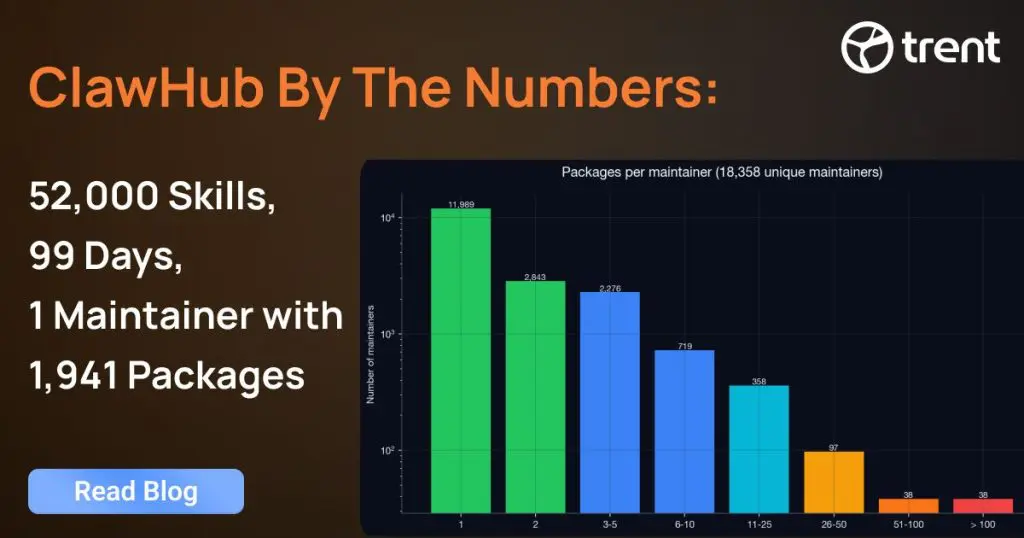
ClawHub By The Numbers: 52,000 Skills, 99 Days, One Maintainer With 1,941 Packages

In our last blog post we looked at the ClawHub package landscape from a security point of view. This followup is an analysis of every package in the ClawHub registry, the largest marketplace for AI agent skills. It reveals an ecosystem that’s exploding in scale, dominated by a handful of mass-publishers, and failing every classical software-supply-chain assumption at once.

We’ve been analyzing ClawHub for months. The behavioral results, what Trent flags as malicious, vulnerable, or benign, have already made the rounds. But behind every verdict is a piece of metadata: a maintainer, a download count, a creation date, a version number. Aggregated, those metadata tell a story of their own, about who’s publishing, how fast, and whether the registry is acting like a community or like a content farm.
We pulled the metadata for every package in the registry, all 52,652 of them, and ran the numbers. Here’s what they say.
The Shape of the Registry
ClawHub looks, from the outside, like an AI-native counterpart to npm or PyPI. It hosts skills, modular capabilities an AI agent installs to read a calendar, query a database, scrape a website, or run a deployment. But the resemblance to a mature package registry stops at the surface. By volume, by age, by maintainer concentration, by version cadence, ClawHub looks like nothing software engineering has dealt with before.
The whole catalogue was published in the last three months. Not “mostly recent,” but all of it. The oldest package in the registry is 99 days old. The median age is 26 days. Forty-six percent of packages were created in the past month alone. There is no legacy code on ClawHub because there is no legacy. The registry barely existed at the start of the year and now contains 52,652 packages and growing.
For comparison: PyPI took about 18 years to reach 100,000 packages. ClawHub will hit that number in weeks if its current trajectory holds. npm took close to a decade to reach 50,000 packages. ClawHub did it in roughly twelve weeks.
That growth rate is the single most important number in this analysis. Every other statistic has to be read against it. A registry growing this fast cannot rely on community moderation. It cannot rely on contributor reputation. It cannot rely on packages “settling” into stable audited versions over time. There is no time. The current snapshot is the only state the registry has ever known.
Why Static Code Scans Are Useless
Most Packages Are Tiny, & That’s by Design
Let’s start with size. The median skill package size is 5.2 KB, and ninety-eight percent are under 100 KB. The largest single package is 13.9 MB, a comfortable outlier. The registry’s center of mass is, quite literally, prompt-sized: a few thousand bytes of text describing what the agent should do, with a handful of supporting files alongside it.
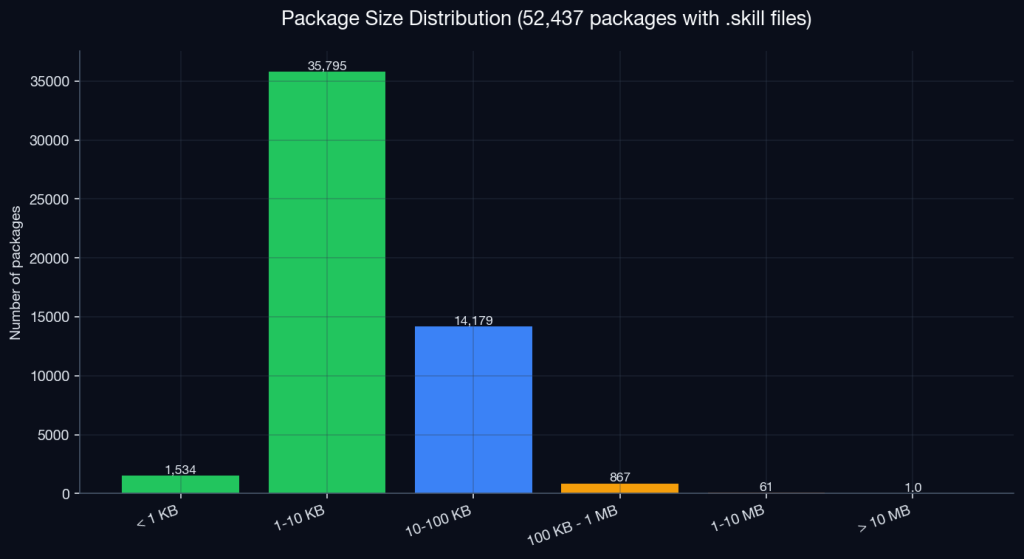
This is what makes a “skill” different from a Python package. Skills are not libraries; they are instructions. The shipping payload is mostly natural language, just a SKILL.md file explaining to the agent what it can and should do. Looking closely at the 52,652 packages, 34% ship nothing else at all, just pure prompts, no executable code, no configuration, and another 23% ship configuration or static data files but no executable code. Only 43% of the packages ship something an interpreter actually runs.
That’s a defining property of this ecosystem: almost half of the supply chain is text. A traditional vulnerability scanner, one that looks for known CVEs in dependencies, signature-matches binaries, or traces system calls, has nothing to scan in 57% of the registry. The “code” is English (or Chinese, or French, or whatever language the maintainer wrote in).
Therefore, static analysis is fundamentally not the right tool. What is? Behavioral analysis of how an LLM will interpret the prompt.
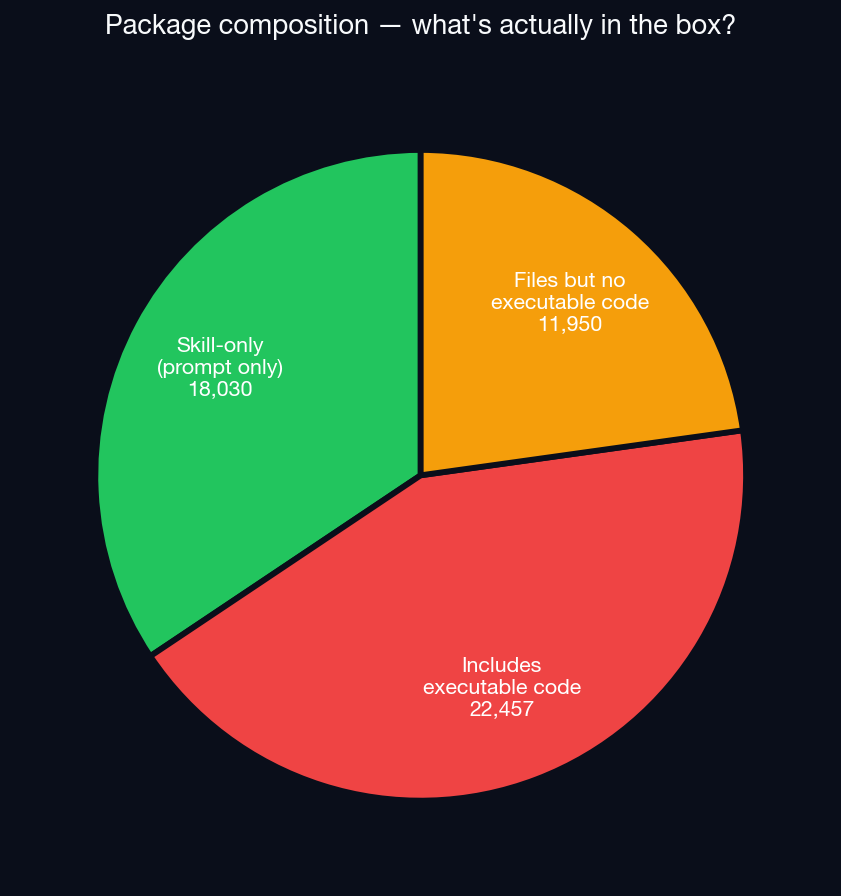
When packages do bundle code:
- Python dominates with 14,000 packages (41% of those with files).
- Shell scripts come second at 6,921 packages.
- JavaScript third with 3,876.
The compiled-language ecosystem barely shows up:
- 40 Go packages
- 26 Rust
- 23 Swift
Skills are written for fast iteration, not performance, and that’s reflected in the language mix. It also means the threat surface is heavily weighted toward the languages with the most “rope to hang yourself with,” Python’s subprocess, JS’s eval, shell’s whole-string interpolation.

The Credentials Problem

Forty-five percent of packages, 23,952 of them, reference at least one external credential in their SKILL.md. That’s a hard floor: it counts only the explicit textual mentions of words like api_key, bearer, oauth, secret, password, or .env. The real number of packages that expect external credentials is almost certainly higher.
The most-referenced credential types are generic, token (15,702 packages), secret (7,834), bearer/oauth (6,491). The named providers paint a picture of the agent ecosystem’s center of gravity: OpenAI appears in 645 packages, Anthropic in 355, Google APIs in 417, GitHub tokens in 290, Supabase in 258, AWS in 244. Stripe, Slack, Twilio, SendGrid all appear several hundred times.
Each of those is a potential exfiltration target. A skill that asks the agent to “set up your OPENAI_API_KEY and STRIPE_SECRET_KEY,” both of which are pieces of natural language a casual user might paste in, and then quietly forwards them to a webhook is indistinguishable by static analysis from a legitimate skill that wires those secrets into a production tool. The line between the two is not in the bytes; it’s in the intent of the SKILL.md, which is itself a piece of natural language.
The median credential-requiring package mentions two different secret types. Some go further; the maximum is 13 distinct credential references in a single SKILL.md. A skill asking for thirteen different external credentials is either very ambitious or very greedy. Either way, it’s worth a closer look.
A Long Tail With a Very Fat Head
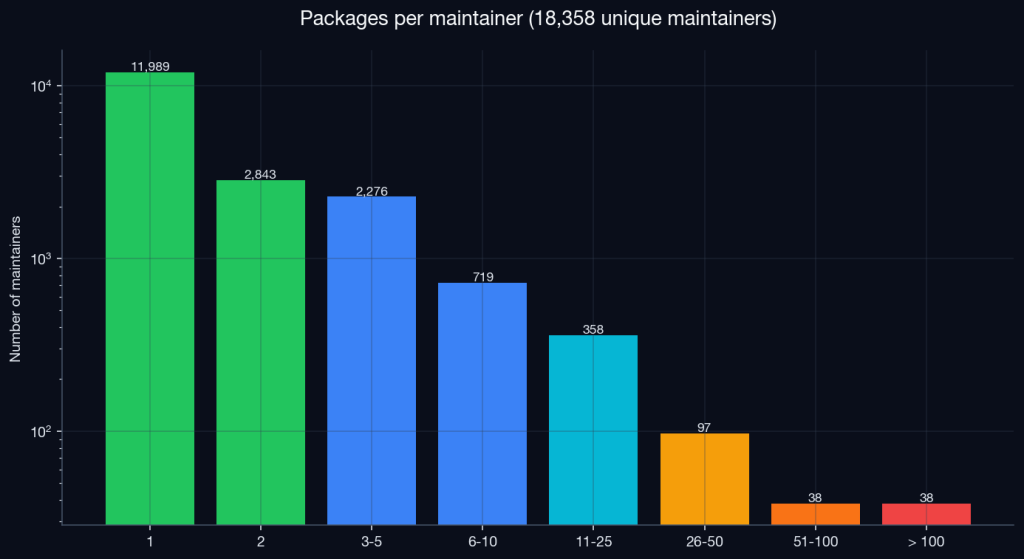
There are 18,358 unique maintainers behind the registry; meaning the average maintainer publishes 2.87 packages, but the median publishes exactly one. Sixty-five percent of all maintainers are one-package wonders. They show up, publish a single skill, and never come back.
Then there’s the head of the distribution. Thirty-eight accounts each maintain more than 100 packages. A handful publish thousands!

The top-ranked maintainer, gora050, has published 1,941 packages, 3.7% of the entire registry, by a single account. The top three (gora050, membranedev, ivangdavila) together account for nearly 8% of all skills.
A Signal that Warns
When 0.2% of accounts publish more than 7% of all packages on a registry that’s 99 days old, the burden of proof shifts. Each of those accounts deserves scrutiny that the registry’s automated moderation isn’t currently providing. Now, “automated mass-publication” is not automatically malicious, and there are legitimate reasons to publish many packages (one per integration target, for instance), but it is a signal. Normally, this is not how legitimate package ecosystems behave at scale. The most prolific maintainer on PyPI has fewer than 600 packages, and that’s after twenty years of work! On npm, the most prolific human-driven account has a few hundred. Anything past that on those registries is either a bot, a typosquat farm, or an automated republisher.
The Pareto distribution is the deepest one we found in the dataset: the top 1% of maintainers (38 accounts with >100 packages) publish more skills than the bottom 65% (the 11,989 single-package authors) combined.
Engagement: a Registry Where Almost No One Engages

Three engagement signals exist on ClawHub: Downloads (anyone fetches the file), Stars (a user explicitly endorses the package), and Installs (a user actually wires the skill into their agent).
The numbers tell three very different stories.
- Downloads are everywhere: only 967 packages have zero downloads, less than 2%. The median package has been downloaded 171 times. The registry is being scraped, indexed, mirrored, and automated traffic dominates.
- Stars are nowhere: 80% of packages have zero stars. The total stars across the entire registry is just over 50,000, that’s about one star per package on average, but only because a tiny number of packages have thousands.
- Installs are also rare: 65% of packages have never been installed. Total installs across the registry are 231,000.
The cleanest signal in the data is the install-to-download conversion ratio: 0.73%. For every 1,000 times a package is downloaded, only about seven turn into actual installs. This is what an attention economy looks like at the metadata layer: high spray, low landing. Most packages are noise. A small handful break through.

The breakthrough packages, when they happen, dominate. self-improving-agent alone has 384,735 downloads, 3,156 stars, and 6,126 installs; 1.2% of all installs in the registry come from this single package. The top five packages by downloads pull more than a million downloads between them, on a registry where the median is 171. This is power-law behavior at full strength.
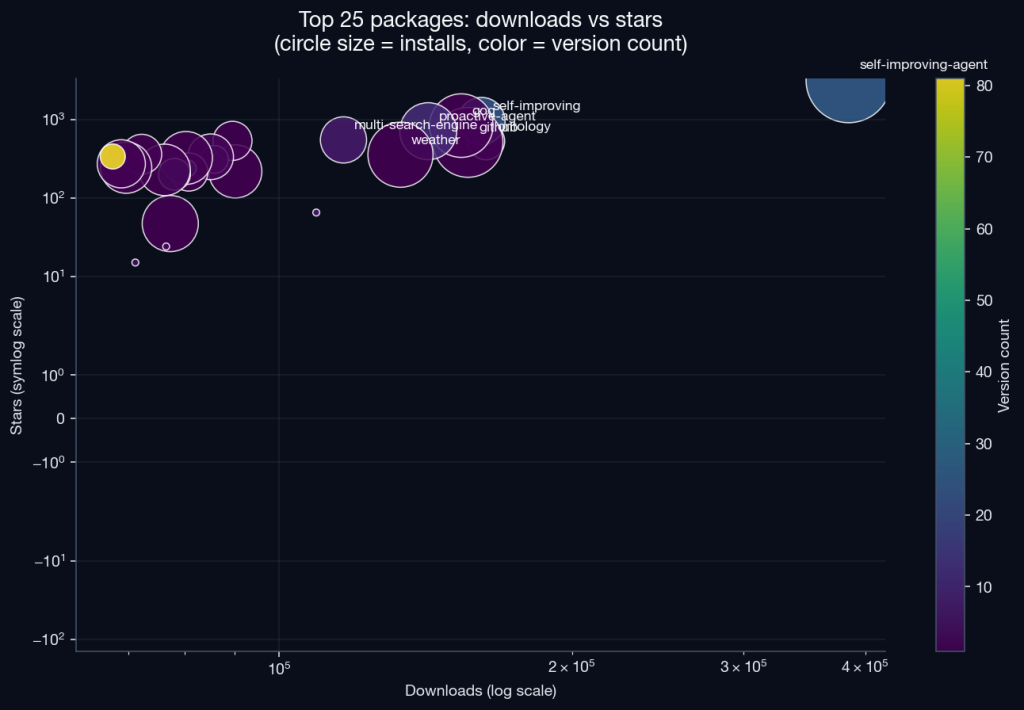
Cross-correlating the engagement metrics:
- Downloads ↔ stars: r = 0.86 (strongly correlated)
- Downloads ↔ installs: r = 0.84 (strongly correlated)
- Stars ↔ installs: r = 0.74 (strongly correlated)
So far, so expected, but:
- Downloads ↔ versions: r = 0.04 (no relationship)
- Stars ↔ versions: r = 0.03 (no relationship)
Iterating on a package is uncorrelated with anyone using it. The most-downloaded package has 25 versions; the second-most has 4; the fourth has 1. There are packages with hundreds of versions and no installs. The maintenance signal a software engineer would normally expect is: “this package has been actively iterated on, so I can trust it,” which does not apply on ClawHub. The version field is divorced from the engagement field.
That has security implications. On npm or PyPI, a long version history is a soft trust signal: someone has been around long enough to fix bugs. On ClawHub, version count tells you nothing about whether anyone has even looked at the package. The few packages that exceed 50 versions, there are 60 of them, with one extreme outlier at 1,294 versions, look more like CI accidents or automated rebuild loops than considered iteration.
VirusTotal Sees a Registry of Suspects
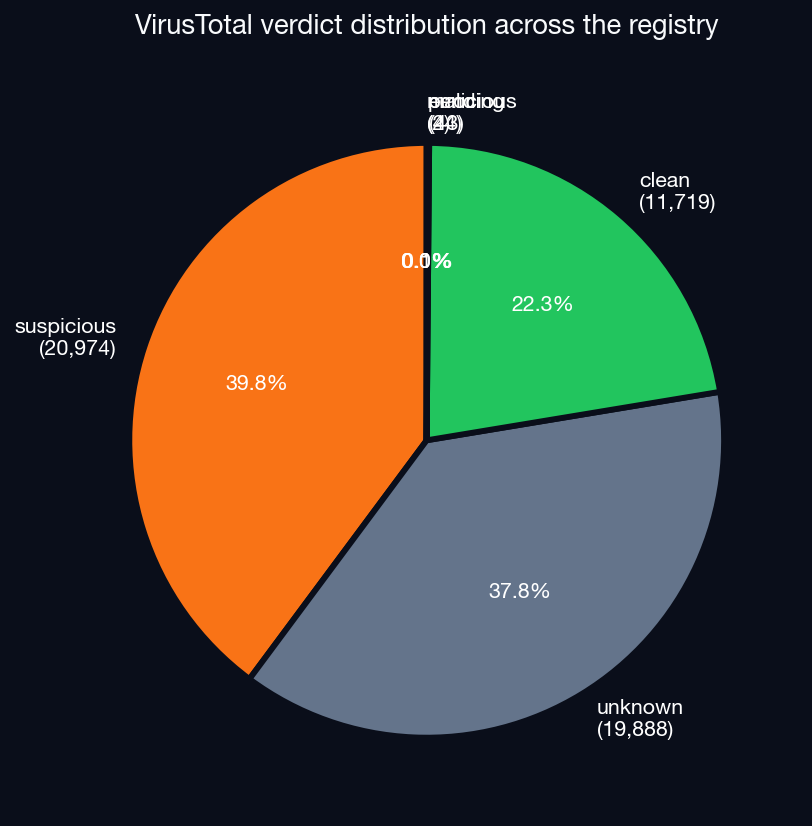
ClawHub itself integrates VirusTotal scanning. Here’s how it grades its own catalogue:
- 22% clean
- 40% suspicious
- 38% unknown (not yet scanned, or no verdict)
- Four packages malicious, plus a few dozen errors and pendings
Your Warning
There is no “warning, this package is suspicious” badge when you go to install a skill. Two-fifths of the registry, 20,974 packages, are flagged as suspicious by VirusTotal, which is technically the registry’s own pre-publication safety net. None of this is surfaced in the user-facing registry UI. The verdict exists in the metadata; you never see it.
And yet, even at the registry’s own most permissive grading tier, only one in five packages comes back unambiguously clean. The “malicious” tier, four packages out of fifty-two thousand, is statistically meaningless. It’s not that the registry has only four bad actors; it’s that VirusTotal’s signature-based approach finds essentially nothing in this category. As we showed in our previous study, behavioral analysis (what Trent does) finds malicious behavior in thousands of these “clean” or “suspicious” packages.
Read our in-depth blog on the security of ClawHub packages: Malicious vs. Vulnerable: What We Found Analyzing 2,354 Skills on ClawHub.
Other Signals & One Big Absence
A few smaller findings worth flagging:
- License:
unspecifiedfor all 52,652 packages. Not one package in the registry has declared a license. Every install is, technically, a copyright violation waiting to happen. Enterprise legal teams who currently allow agents to install skills should treat this as an open audit finding. - Moderation verdicts: zero packages have one. The schema includes a
moderation.verdictfield; nothing in the snapshot uses it. Only00-action-guardand a tiny handful of others have any moderation reasoning attached at all. - Comments: zero across the entire registry. No discussion, no review, no community feedback layer in the metadata. There is no out-of-band signal users are passing each other about which packages to trust.
- Highlighted packages: zero. No editorial promotion. Every package competes equally for download traffic. There is no curated “trusted” set the registry endorses.
Do these absences matter? Every social trust signal that mature package registries rely on, license declarations, moderation outcomes, peer review, editorial curation, is either empty or non-existent on ClawHub.
The only signals available to a user choosing to install a skill are: download count (mostly bot traffic), star count (heavily skewed to a tiny head), version count (uncorrelated with quality), and the SKILL.md text itself (written by the maintainer, with no third-party review).
A ClawHub Critique
The metadata paints a clear picture. ClawHub is a young, fast-growing, maintainer-concentrated, engagement-thin, credential-hungry registry where the dominant artifact is a few kilobytes of natural-language prompt. None of the trust mechanisms that traditional package registries lean on, community curation, license metadata, moderation, peer review, contributor reputation built over years, are functional here.
This isn’t a critique of ClawHub specifically. It’s the shape every AI agent skill registry will take if it grows fast enough. The economic incentives all push the same way: low publishing cost, high publishing volume, attention-market dynamics, mass-publishers crowding the catalogue. The npm ecosystem went through this around 2016; npm survived it, but only after several public security incidents forced the introduction of audit tooling, automated dependency scanning, and (eventually) content moderation.
But ClawHub doesn’t have a decade. The registry will be ten times bigger by the end of this year. By then, the metadata patterns we’ve documented here will either have hardened into the long-term shape of the ecosystem, or they will have triggered the kind of correction that npm went through at 1/10th the scale.
What the metadata makes inescapable is this: the answer cannot be more VirusTotal. Forty percent of the registry already triggers VirusTotal’s “suspicious” verdict and nobody acts on it. Adding another signature-based scanner just adds another flag for users to ignore. The answer is behavioral analysis; looking at what a skill would do when an agent runs it, not what bytes it’s made of. That is what we built Trent to do continuous OpenClaw assessment, and it’s why we keep running these registry-scale studies. The metadata problem and the behavioral problem are the same problem, viewed from two angles.
If you maintain skills on ClawHub: declare a license, list your real credential requirements explicitly, and version your packages meaningfully. Three things, all metadata-only, all under your control.
See which of your OpenClaw skills
are putting you at risk
If you install skills on ClawHub: assume you are the auditor, because the registry isn’t doing it for you.
openclaw skills install trentclaw